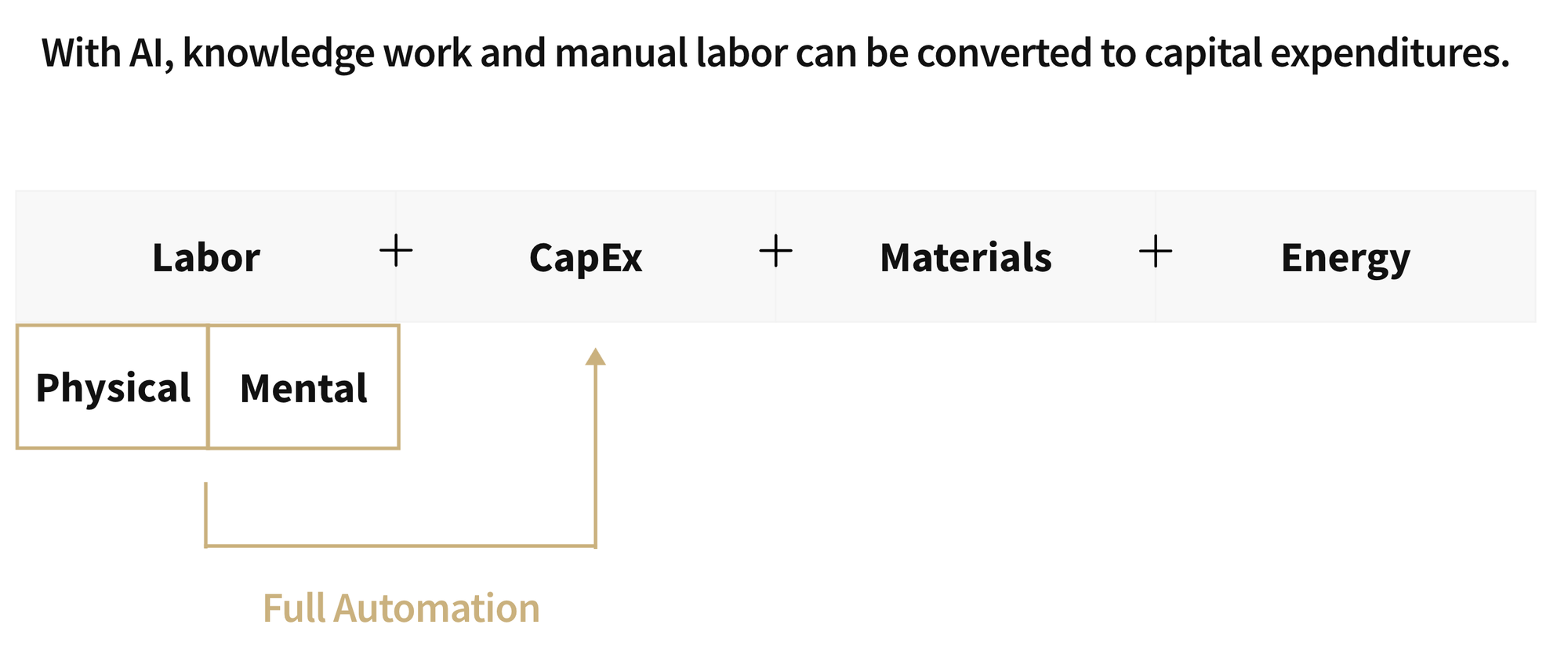
Since the release of ChatGPT (enabled by GPT 3.5) in 2022, the default narrative has been one of AI takeoff and divergence. The imagined scenario is one where a leading AI lab develops a recursively self-improving model. In doing so, there is an intelligence explosion. That leading lab (and the nation behind it) then uses that model to diverge from the rest of the market to become strictly dominant across domains. AI 2027 is a canonical piece exploring (and supporting) this type of scenario. Evidence for this can be found in charts like the one below from METR (a leading independent model evaluation group). With the GPT-5 release on August 7th, 2025, it looks like we are taking off …

There are important, observable political and capital allocation implications to divergence being the “default” view. Under the Biden administration, this drove proposals to constrain model development and curtail chip exports to adversaries to gain a one time advantage in the race to super intelligence. This is in contrast to a path where the US sells Nvidia chips openly to ensure foreign models remain reliant on US technology in the long run. Many of these approaches have continued under Trump, although recent policy announcements indicate a shifting tide.
Whether or not you believe (and believe others believe) we are headed towards a divergent or convergent future of model performance, is core to any forward looking assessments of technology or (geo)politics. Thus what we found most significant about the release of GPT-5 is that, despite its impressive performance, it gave some of the best evidence for a convergent future of AI (based on current model architectures).

Historically, when OpenAI releases a new frontier model, they have dominated across those benchmarks.

In a convergent scenario, instead of seeing a widening gap between the top frontier model and the rest, we would expect to see frequent swaps at the top of benchmarking leaderboards. Frontier performance clusters as improvements become more and more incremental. With GPT-5, they did not. Whether or not you adopt the belief that foundation model performance is converging, at the very least you should re-weight your expectations. We have.
Implications of Convergence
Once you assume a convergent view, you begin to see a much longer journey to AI integration across workflows. Although even the existing abilities of foundation models have created a massive “product overhang” in terms of getting these capabilities in the hands of businesses, converting these capabilities into measurable outcomes is actually very very hard.
Take coding, a domain where these models “excel”. According to a randomized control trial by METR in early 2025 (the same group that released the breakout looking chart at the beginning), AI coding tools made experienced open source developers 19% slower in solving large, complex engineering tasks. This is despite the fact that these same developers believed both before and after trial that AI coding tools would speed them up by over 20%!

We see two drivers of this phenomenon. The first driver is psychological. We really want to believe these models make us better because they allow us to be lazy. Instead of having to think hard, you can queue up a bunch of tasks that agents execute on your behalf. While they are executing you “productively do other work” (or just scroll something) and then come back to evaluate / integrate the outputs. Verification is the lazy man’s execution.
This leads to the second technological driver. The models are not reliable enough over long periods of time. Once again based on METR’s research, the chart below shows the length of time a task can take and still be accurately executed by an agent at a given threshold (from 50% and extrapolating to 99%). The problem in businesses (especially the industrial customers we care about), AI agents need 99%+ accuracy. These tools do not sit in a silo, they are a link chain of multiplicative processes and the chain is only as strong as its weakest link.

Jamin Ball from Altimeter captured this point well in his piece, The Return of Software:
The real value is in the workflows … Those workflows can number in the hundreds, spreading into sales, finance, support, billing, compliance, and a tangle of custom tools. These tentacles are difficult to replace, and companies are hesitant to try. Break one connection and you risk customer-facing impact, which is not a gamble most teams want to take.
Even if you could “vibe code” a drop-in replacement, you still face the hard part: maintaining the core system and all of its tentacles over time. That means upgrades, security reviews, uptime guarantees, and endless support for edge cases.
The fact that extracting measurable enterprise value from these models is more difficult than the market seems to have expected makes investing in AI-enabled products more attractive to us not less. As Balaji Srinivasan (ex a16z / CTO of Coinbase) eloquently put it, these models are “middle to middle” not “end to end”. Not only do they show near zero ability to establish their objectives, but they require heavy prompting (one end) and verification (the other end) to be useful. This is precisely the opportunity for investing at the application layer of AI and the origin of what we call the long beginning of AI.
The quality of the product and service workflows that vertical AI companies develop around foundation models (to bridge the reliability gap) matters deeply to delivering outcomes to enterprises. It is not as simple as winning the AI land grab by being a first mover in a vertical (although that can produce advantages). It requires solving the context dependent AI reliability problem and doing so in a manner that does not rely on run-away token consumption that erodes long-term business model viability.
Don’t Sell Tokens, Sell Services
In our last essay, Embedded Advantage, we argue that the right way to build in industrials is to lead with services, not software. Industrial companies buy results, not features. They have lived with low software penetration because “mostly works” breaks real operations. These companies outsource operational risk to best in-class service providers. A services model earns trust by standing in the flow of work, taking responsibility for outcomes, and learning the local realities of each site/installation. Once that reliability is proven, the repeatable pieces can be productized into software and partially automated internally with foundation models (i.e. without exposing them directly to customers). As shown below, there are a wide variety of services that can be tackled with this approach.
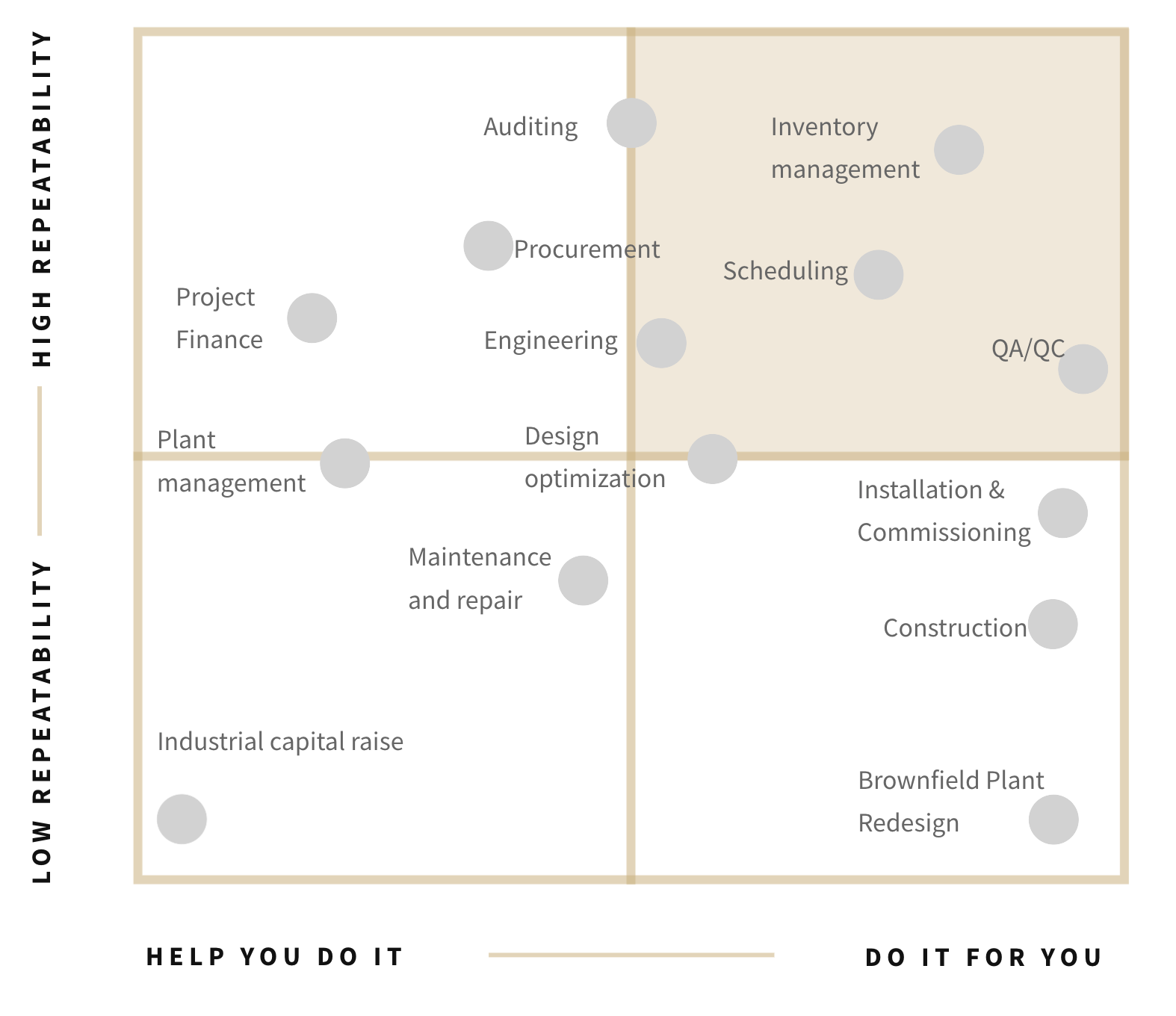
In June, the well known podcaster and AI commentator, Dwarkesh Patel, wrote a piece titled, “Why I don’t think AGI is right around the corner.” The crux of the piece is that the lack of continual learning (the ability to retain and compound firm-specific feedback like human employees) blocks the use of AI in many real workflows (including his own). He argues current LLMs don’t “get better” with you. This is precisely what the services approach solves for. A services company can continually learn at the firm level to ensure reliable outcomes, while internally optimizing operations with (various and potentially interchangeable) AI models. Eventually, if internal AI enabled tooling exceeds greater than 99%+ reliability, it can be sold as a SaaS product (but importantly not until that point if you want to avoid the devil that is churn).
Sustainable Economics
The feather in the cap for the services approach is that, structurally, it avoids the economic Achilles heel of vertical AI solutions. That Achilles heel is selling raw tokens. Many vertical AI products fix their price and then allow their customer to variably consume tokens. In these cases, the more users lean on top-tier models, write longer prompts, and click “run again,” the faster their margins collapse. Your best customers become your downfall.
This was exemplified by the acquisition of the AI coding platform, Windsurf. At roughly ~$80M ARR, usage of expensive frontier models pushed gross margins negative (at least for some customers). After the $3B OpenAI deal collapsed, Google executed a $2.4B license-and-talent pickup, and Cognition acquired the remaining business for ~$250M (including $100M in cash on hand). That’s an $80M ARR company acquired for a 2x multiple.
A services model avoids the trap. When you sell a service, you charge for the result, not the API call. By internalizing model usage, you control your cost structure. Ideally you even use platforms like Cline to provide an abstraction layer between you and the foundation models. As Chris Paik at Pace Capital and an investor in Cline notes, this gives your business a cost and capability tailwind. When an inference provider lowers prices due to competition, every Cline user gets a cheaper product. When a new frontier model comes out, every Cline user immediately gets a better product.
Simply put, as the general purpose technology improves and competition due to convergence drives price down, your business improves too. The phrase we keep in mind is “the product is not the model”. Like with our investment in Hedral in the structural engineering space, we plan to invest in more startups using this approach.
The Big Takeaways
We see increasing evidence for the diffusion of transformer based AI models to follow Carlota Perez’s canonical chart. We may still be in the frenzy, but there are signs (lack reliability, lack of measurable performance improvements, shaky economics) that indicate that getting AI models used in the workplace will require high quality teams designing high quality products and services around foundation models (incredible) abilities and (clear) limitations.
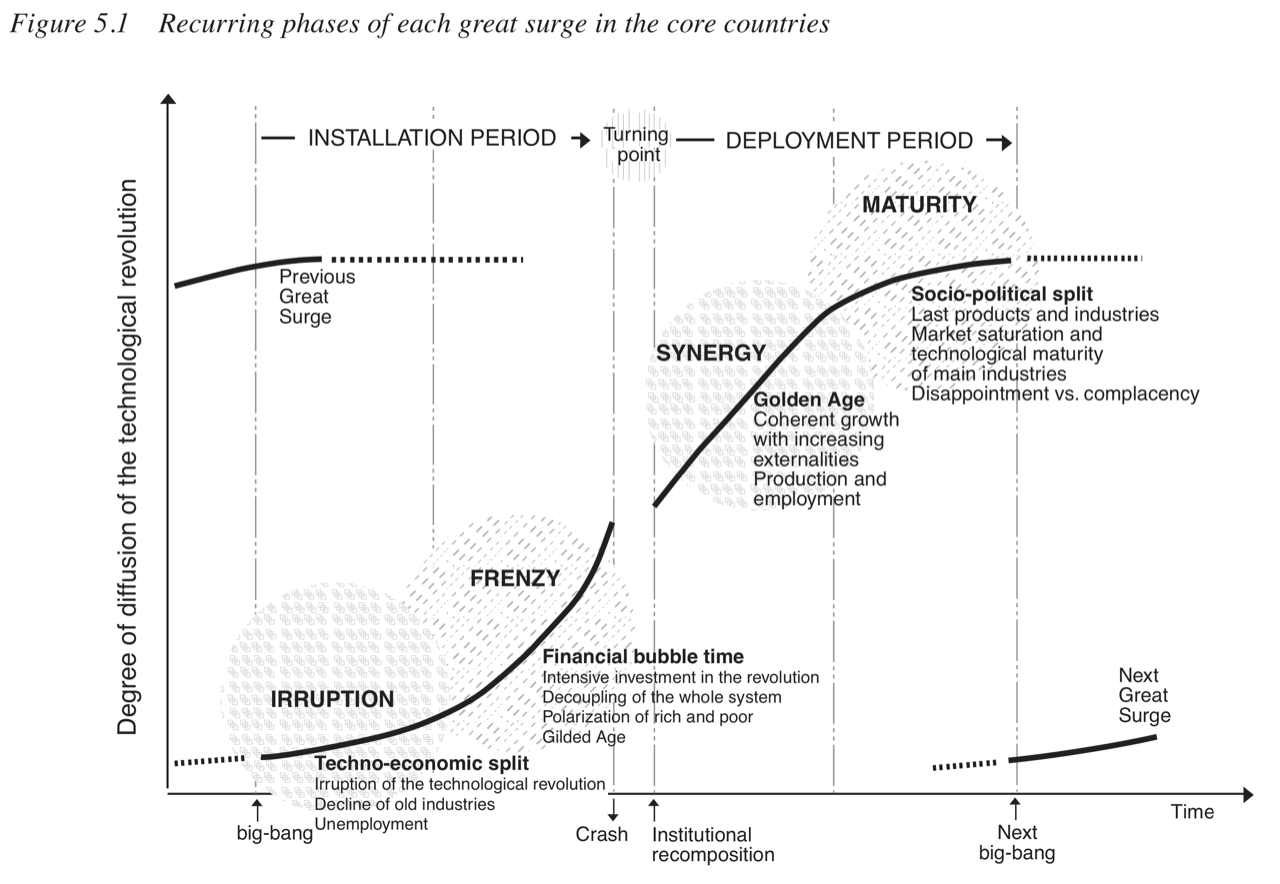
This has important implications for policy and our investing.
- Energy → we believe we are likely over-estimating near-term energy demands from AI while still underestimating our long term needs.
- Chips → to date, US chip policy toward China has been predicated on “AI take-off” panic. Instead we believe we should focus on preserving long-run leverage. This means selling China advanced US chips. This will channel demand to US products / platforms, keep China dependent on allied supply chains, and lower the incentive to build rival AI stacks or escalate over Taiwan.
- Jobs → despite all of the progress with foundation models, they still require humans in loop to provide sufficient context and direction to operate effectively. They also require verification and repeated use to deliver reliably. Job loss due to AI is likely overhyped. Rather, as with all general purpose technologies, those that use it best will stand to gain / replace those that do not.
In the end, we are incredibly excited about the period we are entering. We firmly believe we are entering a new techno-industrial paradigm (enabled by AI). It just turns out that unlocking this transition will require talented builders tackling hard problems (not just basic wrappers around foundation models). This is the long beginning we will be investing behind.